Wahrscheinlich eher unbemerkt hat Adobe im Hintergrund viel an der Verbesserung Ihrer KI basierten Sprachverbesserungssoftware gearbeitet und nun die Version 2 herausgebracht.
Hier sind die Highlights von v2:
Natürliche Klarheit: Klare, natürliche Dialoge ohne Robotertöne – unabhängig von Sprache oder Aufnahmebedingungen. Es kommt mit allem zurecht, von lauten Menschenmengen bis hin zu schlechter Akustik, und liefert Audio in Studioqualität.
Stärkeregler: Angetrieben von unserem Sound Lift AI-Modell können Sie mit dem aktualisierten Regler die Sprachverständlichkeit mit Umgebungsgeräuschen in Einklang bringen. Sie möchten ein bisschen Café-Atmosphäre in Ihrem Podcast? Passen Sie den Regler an, um die perfekte Mischung zu finden.
Rauschunterdrückung: Hintergrundgeräusche, Nachhall und Musik – v2 entfernt alles und hält Ihre Botschaft klar und deutlich.
Enhance Speech v2 kann man hier ausprobieren:
https://podcast.adobe.com/enhance
Mein Test und Fazit
Ich habe es mit folgendem Testszenario getestet: Ich gehe davon aus, dass ich als sagen wir mal junger Journalist auf einem Konzert bin und jemanden interviewen möchte. Im Hintergrund spielt die Band auf der Bühne und es ist laut, viel Lärm von der Menge, andere Stimmen im Hintergrund usw. Ich verwende ein Smartphone als Aufnahmegerät (in meinem Fall ein iPhone). Um dieses Szenario zu simulieren, habe ich auf YouTube ein Live-Konzert gesucht, es über einen Bluetooth-Lautsprecher oder etwas Ähnliches abgespielt und das Smartphone als Mikrofon verwendet, um dieses inszenierte/fiktive Interview mit mir selbst aufzunehmen.
Nach dieser Aufnahme lade ich diese Datei einfach in die verbesserte Sprache hoch.
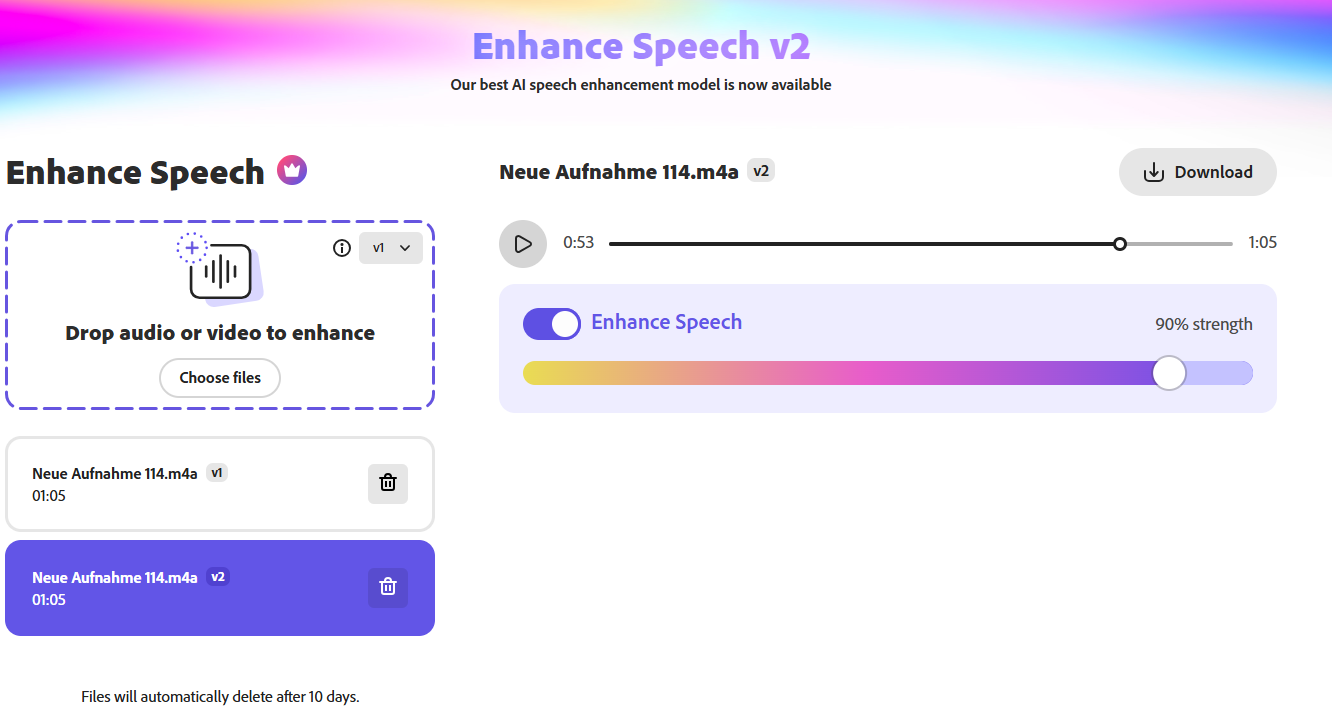
meine Ergebnisse:
Die Tools machen einen ziemlich guten Job! V2 ist definitiv viel besser, keine „Roboterstimme“ mehr usw., wenn es darum geht, die Stimme zu verbessern, aber so ganz fertig ist das Ganze noch nicht. Ich denke wenn da jetzt noch einige Toolverbesserungen gemacht werden dann passt das. Insbesondere wenn sich das Hintergrundgeräusch während der Aufnahme ändert, ändert sich auch die Stimmfarbe und das ist ein bisschen seltsam. Wenn der Hintergrund viel lauter ist als die eigene Stimme oder wenn eine erkennbare zweite Stimme im Hintergrund spricht und Sie eine Pause machen, wird auch die Hintergrundstimme als die eigene Stimme erkannt.
Für den Test wurde als Konzerthintergrundgeräusch „Jennifer Lopez Performs „Dinero“, „I’m Real“ And More | MTV VMAs | Live Performance“ (von MTV UK unter Creative-Commons Lizenz) verwendet wenn es jemand nachmachen möchte.
Hier mal meine Testaufnahme ohne Enhance Speech:
Das Smartphone ist hierbei ca. 10cm vom Mund entfernt und der Bluetooth Lautsprecher am Anfang 30cm, zwischendrin ca. 60cm und zum Schluß 5cm vom Mikrofon des Smartphones entfernt.
Hier zum Vergleich das Ganze mit 90% Enhance Speech in der V1 Version:
Hier merkt man noch deutlich die Roboterartige Stimme, abgehakte Sprachfetzen (mal genauer zwischen 0:04 und 0:07 hinhören) bis hin zu totalen Verzerrungen (mal genauer bei 0:57 bis 1:04 hinhören). Man achte auch auf die P-Laute (Plopp Laute) wenn ich Worte mit „P“ am Anfang ausspreche.
Hier zum Vergleich das Ganze mit 90% Enhance Speech in der V2 Version:
Hier sind dann keine Sprachverzerrungen mehr zu merken, keine Sprachfetzen oder Ausfälle. Ebenso wird die Sprache sobald es lauter im Hintergrund wird nicht mehr so arg verändert und klingt wirklich viel natürlicher.
Fazit:
Alles in allem eine enorme Verbesserung des Tools und in der jetzigen Form grundsätzlich gut nutzbar.
Ich würde mir aber noch Verbesserungen des Tools um „Enhance Speech“ aussenherum wünschen, ein paar mehr „Bedienknöpfe“ wünschen, z. B. Sprachverbesserung, Intensität der Hintergrundüberlagerung, Stimmfarbe (mehr/weniger Radiostimme), mehr/weniger Komprimierung, mehr/weniger KI-Analyse usw.
Im Moment lässt sich das Ergebnis dann als WAVE File abspeichern (da kommen vielleicht auch mal andere Formate dazu) wobei man schnell zwischen der Stärke (strength) wählen kann und beim „download“ wird dann genau die Stärke verwendet. Man kann also sehr schnell die gleiche Aufnahme z.B. einmal mit etwas mehr Hintergrundmusik und einmal mit weniger Hintergrundmusik abspeichern.
Außerdem eine Trennung der Stimmen als Einzelspuren (Stimme1, Stimme2, Hintergrundmusik usw.), damit diese später im Adobe Podcast Studio oder Adobe Audition separat bearbeitet werden können. Ein Button „Mit Audition bearbeiten“ und „Mit Studio bearbeiten (Beta)“ wird ebenfalls noch benötigt. Ich könnte mir das Ganze wenn es dann mal fertig ist auch gut als VST Plugin für Adobe Audition oder andere DAW’s in der Musikproduktion vorstellen. Vielleicht klappt das ja.



